دلیل تفاوت در طول پیامک فارسی و انگلیسی
شاید تا به امروز تصور میکردید که فرقی نمیکند که کارکترها فارسی باشند یا انگلیسی، هر کارکتر یک فضای مشخص را اشغال میکند. احتمالاً متوجه شدهاید که محدودیت تعداد کارکترها در پیامکهای فارسی تقریباً نصف کارکترها در پیامکهای انگلیسی است. حال این پرسش مطرح میشود که چرا کارکترهای فارسی بیشتر از انگلیسی فضا اشغال میکنند؟
برای آزمایش این موضوع یک فایل متنی توسط نرمافزاری همچون Notepad ایجاد کنید و در آن یک کارکتر انگلیسی مانند a را وارد نمایید و فایل را ذخیره کنید حجم این فایل ۱ بایت خواهد بود. این آزمایش را با یک کارکتر فارسی مانند «ب» تکرار کنید؛ این بار حجم فایل ۲ بایت خواهد بود. دلیل این موضوع چیست؟ چرا کارکترهای فارسی فضای بیشتری را نسبت به کارکترهای انگلیسی اشغال میکنند؟
پاسخ این پرسش آسان است؛ حروف انگلیسی بر اساس الگوی کدگذاری به نام ASCII طراحی شدهاند. ASCI مخفف American Standard Code for Information Interchange است و اولین بار در سال ۱۹۶۷ در ایالات متحده امریکا مورد استفاده قرار گرفت. در اَسکی هر کارکتر انگلیسی یک بایت فضا اشغال میکند. کارکترهای انگلیسی بخشی از کارکترهای لاتین به شمار میروند که اسکی به خوبی از آنها پشتیبانی میکند. در زبان انگلیسی ۲۶ حرف وجود دارد که فارغ از اینکه بزرگ هستند یا کوچک، فضای یکسانی از حافظه را اشغال میکنند. در شکل زیر میتوانید جدول کد اسکی را مشاهده نمائید.
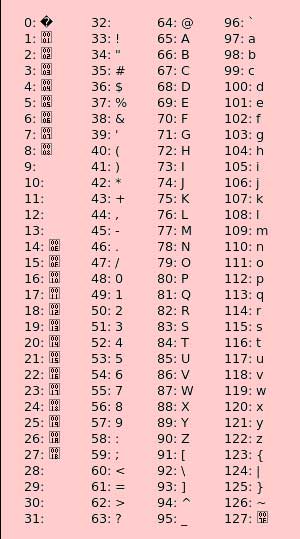
کدهای اَسکی برای الفبای انگلیسی
در دهه ۱۹۶۰ و زمانی که کامپیوترها از حافظه ذخیرهسازی بسیار محدودی بهره میبردند، استاندارد ASCII خلق شد تا کارکترها به روش استانداردی در حافظه تمام کامپیوترهای عرضه شده در آمریکا، ذخیره شوند. در آن زمان تصمیم گرفته شد تا با تکنیک خاصی هر کارکتر در ۸ بیت معادل یک بایت ذخیره شوند. در واقع هر کارکتر انگلیسی ۷ بیت فضا اشغال میکند و بیت هشتم برای چککردن زوج یا فرد بودن عدد است.
با راه یافتن کامپیوتر به کشورهای مختلف جهان و نیاز به واردنمودن زبانهای مختلف دنیا که هر کدام کارکترهای خاص خود را دارند، استانداردهای کدگذاری مختلفی تعریف شد که از جهات گوناگون با ASCII متفاوت بودند. معروفترین این استانداردها که امروزه بسیار مورد استفاده قرار میگیرد و پشتیبانی بسیار خوبی نیز از زبان فارسی دارد، Unicode است. در یونیکد، تمام کارکترهای زبانهای مختلف دنیا در قالب یک مجموعه کارکتر ذخیره شدهاند. معروفترین روش در کدگذاری یونیوکد، UTF-8 است که امروزه بیشتر از باقی استانداردها مورد توجه قرار گرفته است. این استاندارد به شکلی طراحی شده است که از استانداردهای دیگر از جمله ASCII پشتیبانی کند. در UTF-8 هر کارکتر ۲ بایت یا بیشتر فضا اشغال میکند. در شکل زیر جدول یونیکد نمایش داده شدهاست.
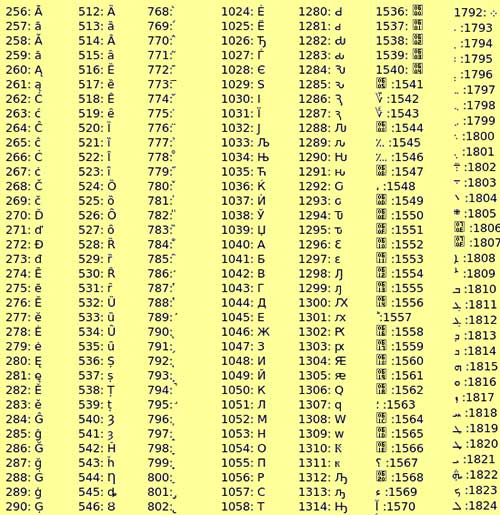
کدهای یونیکد یوتیاف-۸ برای الفبای غیر انگلیسی
پس از آنجایی که حروف انگلیسی براساس استاندارد ASCII ذخیره میشوند یک بایت فضا اشغال میکنند و حروف فارسی نیز که عموماً براساس استاندارد UTF-8 ذخیره میشوند ۲ بایت یا بیشتر فضا اشغال میکنند.
با توجه به این توضیحات اگر در حال ارسال پیامک انگلیسی باشید ۱۶۰ بایت یا ۱۶۰ کارکتر انگلیسی در اختیار خواهید داشت و این در حالی است که این محدودیت برای پیامکهای فارسی به کمتر از نصف کاهش مییابد.
اطلاعات استخراج شده از: خبرگزاری میزان | Mizan Online News Agency






